 |
XML expliqué aux débutants
|
| Cet article, destiné aux novices en matière de XML, ne
suppose aucune connaissance préalable de l'Internet, du WWW ou de
la documentation électronique. Il est illustré par des exemples
élémentaires reproduits sous forme d'images "copie d'écran",
qui de ce fait peuvent être visualisés par tout logiciel de
navigation (butineur) apte ou non à traiter du XML. Le lecteur désireux
de manipuler réellement ces exemples ne pourra toutefois le faire
que s'il dispose du butineur Internet Explorer 5 de Microsoft (MSIE5).
Ce logiciel est actuellement le seul butineur grand public apte à
traiter du XML. Il est extrêmement facile de se le procurer : la
plupart des revues consacrées au WWW le proposent sur leur CD-ROM
d'accompagnement. Il est également possible de le télécharger
: voir notre page Commencez dès
aujourd'hui à manipuler du XML.
Vos commentaires, critiques et suggestions sur le contenu et la présentation
de cet article sont les bienvenus. |
XML (Extensible Markup Language, ou Langage Extensible de Balisage)
est le langage destiné à succéder à HTML sur
le World Wide Web. Comme HTML (Hypertext Markup Language) c'est
un langage de balisage (markup), c'est-à-dire un langage
qui présente de l'information encadrée par des balises.
Mais contrairement à HTML, qui présente un jeu limité
de balises orientées présentation (titre, paragraphe, image,
lien hypertexte, etc.), XML est un métalangage, qui va permettre
d'inventer à volonté de nouvelles balises pour isoler toutes
les informations élémentaires (titre d'ouvrage, prix d'article,
numéro de sécurité sociale, référence
de pièce
), ou agrégats d'informations élémentaires,
que peut contenir une page Web.
Le prédécesseur de XML sur le
Web : HTML
Pour comprendre la philosophie de XML, rien de mieux qu'un petit exemple.
Prenons pour ce faire une page énumérant la (maigre) bibliographie
en langue française sur XML (à rapprocher des dizaines d'ouvrages
existant en anglais sur le même sujet). Voici comment une telle page
pourrait se présenter (avant interprétation par le logiciel
de navigation, ou "butineur") si elle était codée selon le
langage actuel du Web, HTML :
<H2>Bibliographie XML</H2>
<UL>
<LI> Jean-Christophe Bernadac et François Knab, <I>Construire
une application XML</I>, Paris, Eyrolles, 1999</LI>
<LI> Alain Michard, <I>XML, Langage et Applications</I>,
Paris, Eyrolles, 1998 </LI>
<LI> William J. Pardi, <I>XML en Action</I>, Paris,
Microsoft Press, 1999, adapté de l'anglais par James Guerin</LI>
</UL> |
Figure 1. Exemple de HTML
: une bibliographie (avant interprétation par le "butineur")
Figure 2. Le même
fichier HTML, après interprétation par un butineur/traitement
de texte
De HTML à XML
Voici ce que donnerait la même page si elle était codée
en XML :
<?xml version="1.0" encoding="ISO-8859-1"?>
<BIBLIO SUBJECT="XML">
<BOOK ISBN="9782212090819" LANG="fr" SUBJECT="applications">
<AUTHOR>
<FIRSTNAME>Jean-Christophe</FIRSTNAME>
<LASTNAME>Bernadac</LASTNAME>
</AUTHOR>
<AUTHOR>
<FIRSTNAME>François</FIRSTNAME>
<LASTNAME>Knab</LASTNAME>
</AUTHOR>
<TITLE>Construire une application XML</TITLE>
<PUBLISHER>
<NAME>Eyrolles</NAME>
<PLACE>Paris</PLACE>
</PUBLISHER>
<DATEPUB>1999</DATEPUB>
</BOOK>
<BOOK ISBN="9782212090529" LANG="fr" SUBJECT="général">
<AUTHOR>
<FIRSTNAME>Alain</FIRSTNAME>
<LASTNAME>Michard</LASTNAME>
</AUTHOR>
<TITLE>XML, Langage et Applications</TITLE>
<PUBLISHER>
<NAME>Eyrolles</NAME>
<PLACE>Paris</PLACE>
</PUBLISHER>
<DATEPUB>1998</DATEPUB>
</BOOK>
<BOOK ISBN="9782840825685" LANG="fr" SUBJECT="applications">
<AUTHOR>
<FIRSTNAME>William J.</FIRSTNAME>
<LASTNAME>Pardi</LASTNAME>
</AUTHOR>
<TRANSLATOR PREFIX="adapté de l'anglais par">
<FIRSTNAME>James</FIRSTNAME>
<LASTNAME>Guerin</LASTNAME>
</TRANSLATOR>
<TITLE>XML en Action</TITLE>
<PUBLISHER>
<NAME>Microsoft Press</NAME>
<PLACE>Paris</PLACE>
</PUBLISHER>
<DATEPUB>1999</DATEPUB>
</BOOK>
</BIBLIO> |
Figure 3. Exemple de XML
: la même bibliographie
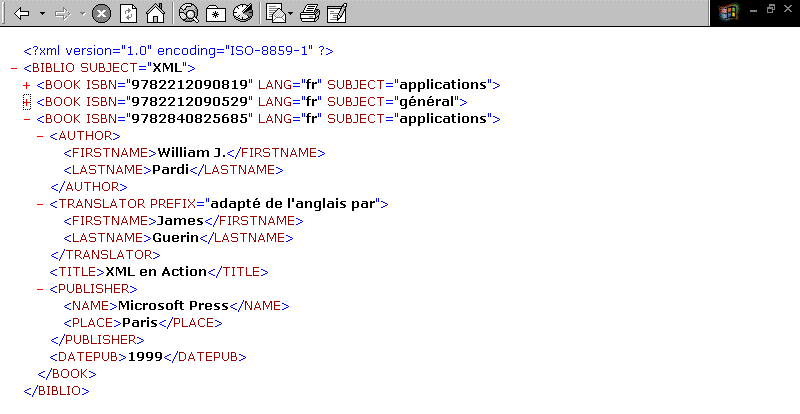
Figure 4. Le même fichier XML affiché par
Microsoft Internet Explorer 5 (en l'absence d'une feuille de style) sous
forme d'arborescence dépliable et repliable (le signe "-" indique
une branche dépliée, le signe "+" une branche repliée)
-- Tester l''exemple (MSIE5 requis)
Les règles du jeu XML
Elles sont extrêmement simples.
-
Les informations doivent être :
-
soit encadrées par des balises ouvrantes(ex. <LIVRE>)
et fermantes (ex. </LIVRE>)
contrairement à HTML où ses ces dernières n'étaient
pas toujours obligatoires). On parle alors d'éléments.
Les éléments doivent s'imbriquer proprement les uns dans
les autres : aucun chevauchement n'est autorisé. Les éléments
vides sont permis, selon le format <ELEMENTVIDE/>.
-
soit incluses à l'intérieur même des balises : on parle
alors d'attributs. Exemple : <LIVRE
SUJET="XML">. Ici l'attribut SUJET de l'élément
LIVRE a la valeur "XML"
. En XML, contrairemet à HTML, les valeurs des entités
doivent toujours être encadrées par des guillemets (simples
ou doubles).
-
Soit encore définies sous forme d'entités. Les entités
sont des abréviations. Par ex; si "Extensible Markup Language" est
déclaré comme une entité associée à
la notation "xml"; cette chaîne de caractères pourra être
abrégée en "&xml;" dans
tout le fichier XML. Une entité peut aussi représenter un
fichier XML externe tout entier. Ainsi un même fichier XML (par exemple
notre bibliographie) pourra être utilisé par plusieurs pages
XML différentes (par exemple une page spécifiquement consacrée
à XSL pourra présenter à la fin la bibliographie spécifique
d'XSL quand elle existera ! extraite automatiquement de notre bibliographie
XML)
-
La DTD (Définition de Type de Document).
La structure arborescente du document XML (intitulé des balises,
imbrications des balises, caractère obligatoire ou facultatif des
balises et de leur ordre de succession
) peut être déclarée
formellement dans le corps du document XML ou dans un fichier à
part. Cette déclaration s'appelle une Définition de Type
de Document (DTD). Elle s'effectue selon un formalisme particulier défini
lui-aussi dans la spécification XML. En XML cette déclaration
est facultative, ce qui donne une grande souplesse aux développeurs.
On n'écrira donc une DTD que lorsqu'il y aura vraiment intérêt
à le faire (par exemple pour contraindre la saisie/mise à
jour du document XML)
Lorsqu'un document XML possède une DTD associée et la
respecte, on dit qu'il est valide. Lorsqu'il respecte seulement
les règles de la grammaire XML (balises fermées, correctement
imbriquées
) on dit qu'il est bien formé.
La spécification XML se trouve à http://www.w3.org/TR/REC-xml.
Sa traduction française se trouve à http://babel.alis.com/web_ml/xml/REC-xml.fr.html
Ce que XML va rendre possible
XML va permettre :
-
de saisir (ou mettre à jour) une seule fois un contenu (par
ex. notre bibliographie) et un contenu pur. Autrement dit :
-
sans se soucier de la présentation ou des traitements futurs ;
-
sans avoir à saisir des libellés tels que'"auteur", "année
de parution", sans avoir à mettre les titres en italique exactement,
donc, à la manière dont on alimenterait une base de données.
-
Et d'en générer ensuite automatiquement :
-
de multiples présentations (en tableau, en texte suivi
)
-
avec éventuellement tris, sélections, réorganisations,
génération automatique de libellés, tables des matières,
index, etc.
-
et ce sur de multiples médias (écran, papier, terminal Braille,
etc.)
Tout ceci rendu possible par l'indépendance du balisage par rapport
à la présentation.
-
aux logiciels de comprendre/exploiter au mieux le contenu de ces pages,
rendu désormais explicite par un balisage spécifique, indépendant
de toute application.
Ci-dessous, un exemple de ce que l'on peut obtenir à partir de notre
fichier XML en l'associant à une feuille de style rédigée
dans le langage de présentation associé à XML : XSL
(Extensible Style Language)
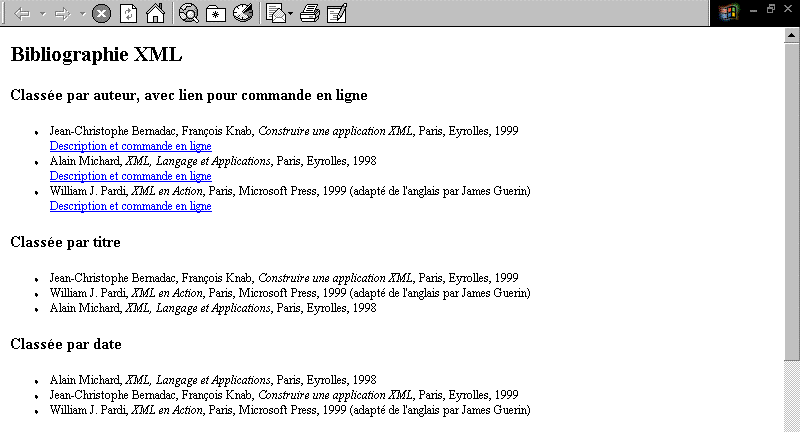

Figure 5. Le même fichier XML affiché par
MSIE5 à l'aide d'une feuille de style XSL. La feuille de style permet
de multiples réorganisations et présentations d'un même
contenu -- Tester l'exemple (MSIE5 requis)
-- Voir la feuille de style XSL
Un autre exemple de ce que l'on peut obtenir en incluant le même
fichier XML sous forme d'"îlot de données" dans une page HTML
comportant un script. Notre page est devenue interactive et permet maintenant
au lecteur de déclencher lui-même le tri de la bibliographie,
à volonté et selon quatre critères différents.
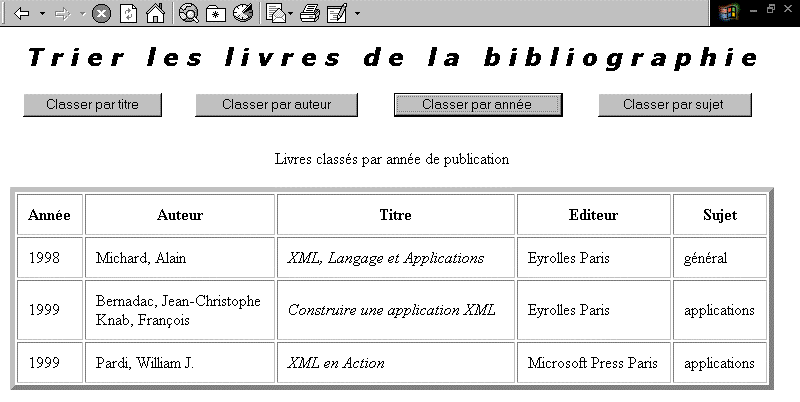
Figure 6. Page HTML (telle qu'interprétée
par MSIE5) incluant le même fichier XML sous forme d'"îlot
de données" et comportant un script permettant le tri interactif
de la bibliographie selon différents critères -- Tester
l'exemple (MSIE5 requis)
L'environnement futur de XML
Cet environnement est pour la plus grande part encore en cours d'élaboration
par le World Wide Web Consortium (W3C).
Il peut donc encore subir des modifications.
Les "espaces de nommage" (namespaces)
Les namespaces, ou "espaces de nommage", sont un mécanisme
destiné à lever les ambiguïtés éventuelles
des intitulés de balise. Par exemple "titre" peut aussi bien désigner
le titre d'un ouvrage que celui d'une personne. Pour lever ces ambiguïtés,
le mécanisme des namespaces consiste à utiliser des
préfixes, par ex. "perso:titre" et "biblio:titre". Ces préfixes
doivent être déclarés comme associés à
une URL qui peut être fictive, mais qui le plus souvent fera référence
à l'organisme garant du vocabulaire en question). Exemple de déclaration
de namespaces :
| <BIBLIO xmlns="http://www.biblio.org/vocabulaire"
xmlns:perso="http://www.personel.org/Profiles/ "> |
Dans cet exemple, les balises non préfixées sont censées
se rapporter à l'espace de nommage par défaut, associé
à l'URL fictive "http://www.biblio.org/vocabulaire", et les balises
préfixées par "perso:" sont censées se rapporter à
l'espace de nommage associé à l'URL non moins fictive "http://www.personel.org/Profiles/"
Les langages de présentation (style) : CSS et XSL
Comme il a été dit, la philosophie d'XML consiste à
bien séparer les données/documents (le fichier XML proprement
dit) des traitements/présentations. Un document donné sera,
lors de sa création, balisé uniquement en fonction
de son contenu (sa sémantique) intrinsèque et indépendamment
de sa restitution future (papier, écran, terminal Braille, synthèse
vocale ou autre) comme d'ailleurs de tout autre traitement automatique
qui pourra lui être appliqué.
Cette indépendance par rapport aux applications qui vont le traiter
en général, et par rapport à celles chargées
de sa restitution en particulier, va lui conférer :
-
une très grande interopérabilité (le même
document XML va pouvoir être affiché sur le Web et/ou produit
en version papier, alimenter un SGBD, etc.)
-
et une très grande durabilité/réutilisabilité
(le document ne deviendra pas obsolète avec l'évolution
des techniques informatiques ; il pourra sans difficulté être
incorporé, en tout ou partie, dans des documents de nature très
différente, être traité par des applications non prévues,
voire non-existantes au départ...).
En ce qui concerne sa restitution, un deuxième degré d'indépendance
par rapport aux applications pourra être apporté par l'utilisation
du langage de transformation normalisé XSLT
(XSL Transformation) qui va permettre, si nécessaire,
de transformer une DTD (un arbre XML) "orientée contenu" en une
autre DTD (un autre arbre XML) "orientée restitution" (c'est-à-dire
constituée d"objets formateurs" (formatting objects). C'est
à ce niveau que l'ordre de restitution final sera établi
(par exemple, que la bibliographie sera classée par ordre alphabétique
d'auteurs), que les légendes du type "figure n° x" seront ajoutées,
que seront fabriqués automatiquement les tables des matières,
index alphabétiques, liens (logiques) de navigation, etc.). Ici
nous sommes encore à un niveau largement indépendant du support.
(Voir la spécification à http://www.w3.org/TR/WD-xslt)
Le langage normalisé de feuille de style XSL
(Extensible Style Language) va permettre ensuite de spécifier
comment un type de document (= une DTD "orientée restitution") donné
va être restitué sur un support donné. C'est à
ce niveau que seront réglés les problèmes du type
"saut de page", notes présentées en bas de page ou en fin
de chapitre, etc., que les liens de navigation seront fabriqués
(hyperliens pour les versions électroniques, renvoi à un
n° de page ou de paragraphe ou de note pour les versions papier...)
(Voir la spécification à http://www.w3.org/TR/WD-xsl)
Une feuille de style XSL est appelée à partir d'un document
XML par une "processing instruction" (PI) selon l'exemple suivant :
| <?xml-stylesheet href="biblio.xsl"
type="text/xsl" ?> |
Le langage normalisé de feuille de style CSS (Cascading Style Sheets)
déjà utilisé avec HTML, pourra également être
utilisé concurremment où à la place de XSL.
Une feuille de style CSS est appelée à partir d'un document
XML par une "processing instruction" (PI) selon l'exemple suivant :
| <?xml-stylesheet href="biblio.css"
type="text/css" ?> |
XML Schema
XML Schema est un formalisme qui doit permettre de définir des contraintes
en matière de syntaxe, de structure et de valeurs applicables à
une classe de documents HTML. Il va permettre entre autres choses d'effectuer
des contrôles de validité lors de la saisie/mise à
jour de documents XML (exactement comme pour la saisie/mise à jour
d'une bases de données). Par exemple, dans le cas de notre bibliographie,
XML Schema va permettre de déclarer que l'élément
DATEPUB doit être une date limitée à l'année,
etc.
Le projet XML Schema se subdivise actuellement en deux parties :
Le Modèle objet de document (DOM Document Object Model)Le
Modèle objet de document est un langage normalisé d'interface
(API, Application Programming Interface) qui va permettre à
un programme (Java, ECMAScript
) de naviguer dans un arbre XML (ou HTML)
et d'en lire ou d'en modifier le contenu
Book = Doc.documentElement.firstChild;
...
Sujet = Book.getAttributeNode("SUBJECT").text;
...
Auteur = Book.selectSingleNode("AUTHOR");
...
Auteur = Auteur.nextSibling; |
Figure 7. Exemple d'utilisation
du modèle objet de document (DOM) : quelques lignes extraites du
script Javascript de la page dynamique présentée en
figure
6
Les langages de lien et d'adressage
Les mécanismes de lien (linking) et d'adressage associés
à XML sont en cours de spécification au sein de trois documents
:
-
XPath (XML Path Language). XPath est le langage
d'expression de chemins à l'intérieur d'un document XML,
destiné à être utilisé à la fois par
XSLT et par Xpointer. Sa spécification se trouve
en http://www.w3.org/TR/xpath
-
XPointer (XML Pointer Language). XPointer est
le langage d'adressage des contenus d'un document XML. Sa spécification
se trouve en http://www.w3.org/TR/WD-xptr
-
XLink (XML Linking Language). XLink spécifie
les indications à insérer dans les ressources XML pour décrire
des liens entre objets. Il utilise la syntaxe XML pour créer des
structures qui peuvent décrire non seulement des hyperliens unidirectionnels
tels que ceux permis aujourd'hui HTML mais aussi des liens plus complexes
typés et à terminaisons multiple. Sa spécification
se trouve en http://www.w3.org/TR/xlink
XML en perspective
Pour terminer nous replacerons brièvement XML dans l'histoire des
documents électroniques. Pour de plus amples développements
à ce sujet on pourra se reporter à notre article Des
Documents qui prennent vie...
La décennie 80 : SGML et les aides en
ligne
SGML (Standard Generalized Markup Language, ou langage normalisé
de balisage généralisé), adopté comme standard
en 1986 (ISO 8879), a été la première tentative systématique
de créer de réels documents électroniques, cest-à-dire
des documents qui n'étaient plus des documents papier sous forme
électronique. La principale idée sous-jacente étant
de séparer le contenu (logique) d'un document de sa forme
(matérielle/imprimée). Mais l'intention finale était
toujours principalement de produire des documents imprimés,
quoique plus économiquement un unique document (logique) étant
transformé automatiquement en différents formats imprimés
(par ex. des documents de maintenance pour des avions produits en différents
formats selon les normes de présentation de différentes compagnies
aériennes ou armées de l'air). SGML a été une
percée, mais il était si complexe que sa manipulation s'est
trouvée restreinte aux spécialistes (rédacteurs techniques
dans l'industrie ou spécialistes textuels dans les humanités).
Presque parallèle a été le développement
de la documentation en ligne, interactive, la première forme de
documentation à être purement électronique. Et avec
elle est arrivée la popularisation des liens hypertextuels. Mais
cette forme de documentation restait une "aide", accessoire à la
documentation papier.
Les années 90 : Le WWW et HTML
A partir de 1992, le WWW et HTML (Hypertext Markup Language, ou
langage de balisage hypertexte, conçu vers 1990) sont devenus une
réalité, et ont popularisé les documents électroniques
hypertextuels sur une immense échelle. Depuis 1995, les moteurs
de recherche ont démontré la stupéfiante capacité
de recherche d'information rendue possible par le WWW.
Ainsi, avant l'apparition de XML, existaient :
-
un langage de balisage normalisé, riche en sémantique mais
relativement lourd à mettre en oeuvre et inadapté au Web
: SGML
-
un langage parfaitement adapté au Web (puisque développé
uniquement pour cette application) mais dont les applications sont limitées
par une bibliothèque de balises figée et réduite :
HTML
Il convenait donc de définir un langage qui ait la facilité
de mise en oeuvre de HTML tout en offrant la richesse sémantique
de SGML. C'est la raison d'être de XML.
XML est un sous-ensemble au sens strict de SGML, dont il ne retient
pas les aspects trop ciblés sur certains besoins. En cela il représente
un "profil d'application" de la norme SGML.
L'avenir prévisible de XML
Il est à prévoir que l'usage d'XML va déborder largement
le WWW, en provoquant la convergence de deux mondes informatiques jusqu'ici
séparés ; celui des documents et celui des données.
Il est très probable qu'il va de ce fait devenir très
rapidement la lingua franca de l'informatique, parlée
tout autant par les SGBD que par les outils de bureautique et de documentation,
par les logiciels de gestion aussi bien que par les applications techniques
et scientifiques. Qu'il va rendre possible une automatisation des activités
administratives et logistiques sans commune mesure avec ce que permettent
les outils d'aujourd'hui. Et qu'il va considérablement simplifier
l'Échanges de Données Informatisé (EDI).
On n'a donc pas fini d'entendre parler de XML !
Notes et éclaircissements
Une balise n'est pas autre chose qu'une
portion de texte spécialement délimitée. En XML comme
en HTML (comme dans leur ancêtre commun SGML) les balises sont encadrées
par les caractères réservés "<"
et ">".